如若轉載,請注明出處:http://www.qyxianhua.cn/product/36.html
更新時間:2026-06-17 18:21:31
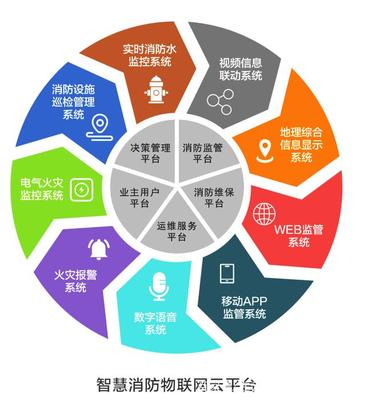
廣西智慧消防物聯網領軍企業 創新驅動與精細管理的雙重引擎
商品服務API基礎之六 品牌與企業管理實踐
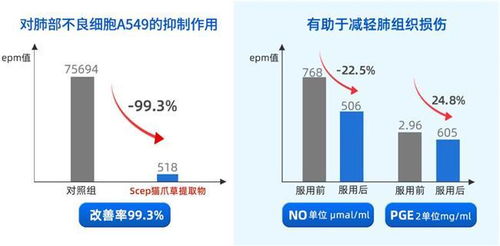
槲皮素品牌選擇指南 十大榜單、安全規范與成分純度雙重解析
一八供應鏈再啟新程 萬里同承的企業管理新篇章
從剎車盤鑄件出口看全球產業鏈變局與企業管理新策略
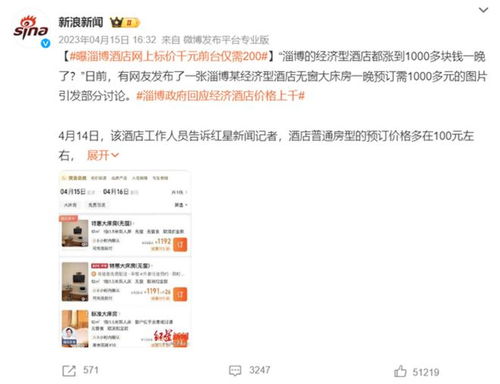
經濟型酒店為何“不經濟”?——從企業管理視角看行業困局
解碼寶潔 品牌量化管理如何塑造全球消費品帝國
品牌騎士 引領中小企業品牌管理新時代
于實踐中強化信用管理 企業品牌管理的核心路徑
B2B品牌營銷八大趨勢 洞察與前瞻
電話:1381815**
地址:上海市閔行區三友路1號3幢101室
Copyright © 2026 www.qyxianhua.cn 品牌管理 上海侑焜品牌管理有限公司 品牌管理 版權所有 Sitemap